


Building AI-first Products
As we stand on the brink of a brave new world of technology, let's explore a few ways to make the most of the paradigm shift playing out right in front of us.

We are now in a momentous age of technology, where machines are gaining the ability to synthetically comprehend, reason and converse like a human. This has the potential to transform the way we interact with computers, software and technology as a whole. After exploring this from multiple critical angles, I have arrived to the same conclusion every time: this shift will be a game-changer for the experience, scalability, and distribution of every sector and industry.
The foundation of this belief is not only the technology itself, but the new paradigms it enables. If one merely considers the technology, they may easily miss the big picture - the technology is still in its infancy and is far from perfect. As with the last few paradigm shifts, something as simple as a 286 PC with a 4mhz CPU and 1mb of memory or just 56 kb/s connectivity can be sufficient to revolutionize the world.
Pure text-based and conversation products are relatively underwhelming manifestations of shipping an LLM (Large Language Model) API directly to the customer. There is much more potential to be explored if we think beyond the confines of familiar human-language products and interfaces. New product development methodologies, models and user experience patterns are required to leverage these new bottomless APIs with probabilistic outputs like LLMs, and eventually, AGI (Artificial General Intelligence). In this post, I’ll cover 5Cs that can be used to bring some structure and product thinking to AI solutions:

Careful consideration and tailoring to the technology's ergonomics can open the doors to unprecedented possibilities. Although the primary focus of this post is LLMs, some of the concepts do generalize broadly to AI/AGI as a whole.

1. Containing the problem space: thinking in domains
There is a lot of domain-specific knowledge baked into the popular foundation models, and this is where most of the meat is in the near term. This can be further refined with domain-specific fine tuning. I’ve been referring to it as ADI (Artificial Domain Intelligence) and this is the most exciting and tangible product, experience and business outcome for AI that’s broadly available today.
We recently saw examples of this with Galactica from Meta for scientific papers and Med-PaLM from DeepMind for clinical knowledge. This is only going to get more common and here’s to hoping for several open source versions for specific industries trained on publicly available and donated data. This is great for businesses that want to automate customer interactions, enable efficient data retrieval workflows from large corpuses, internal process automation, reduce grunt work, simplify data analysis, augment their labor force etc.
Products built with AI need to be clear in the domain-space they’re looking to tackle. This can be broad, i.e comparable depth of knowledge across domains enabling consistent cross-domain experience or narrow with significant depth in a specific domain. Being clear about this helps with clearly structuring the UX and proposition.

Until we have bonafide AGI, ADI can be used to create new products and services that were previously prohibitive due to human-costs, scalability or technical constraints. AI specifically tailored to the legal texts of two countries can facilitate the translation of laws between them, swiftly detect discrepancies and close any potential cavities in considerations that could take hundreds of hours for human professionals to identify. Thinking in domains also narrows the set of new user experiences, journeys and considerations that need to be reconstructed for the new paradigm.
2. Construct the UX: breaking the skeuomorphic barrier
Almost every attempt to bolt AI on top of existing products and paradigms are very likely to miss the boat. We’ve seen products pipe LLM outputs directly into text editors, tables and other existing surfaces to do text generation, summarization, classification etc. While this is useful, but there are no common prior-use cases or behaviors that involve using these surfaces that way. This could also suffer from the inefficient approach of incorporating AI at the task rather than problem level.

Redefining the problem context and rethinking the solutions with the new paradigms enabled by AI leads to some interesting consequences. First, the interface might not look like an editor, table or a page. Second, it forces a decision in the workflow design of a hand-off point from human to machine. Third and possibly most impactful effect, it introduces an additional consideration for if there is a need for human input in the workflow at all. Restructuring the workflow design this way often wipes the slate clean of previous interfaces, APIs and data models - forcing a complete redesign.
When a solution is redesigned to be AI-native, quite often it ends up drastically reducing the complexity of the interfaces with most of the magic happening behind the scenes. After having seen this happen several times now, I’m convinced all existing patterns of human-computer interfaces will need to be redesigned as this paradigm accelerates. Almost all of our interfaces and systems are designed to go from action to action, we’ll now need interfaces to go from objective to objective efficiently.
3. Compose the product stack: simulating proto-AGI
Foundation models are very powerful straight out of the box. They can take instructions and respond with meaningful completions to most inputs, questions or requests. However, a human does the work of decomposing the problem, setting context and sequentially shaping the output to the desired result. In production-grade AI products, this needs to happen behind the scenes and be fully done by machines.
To enable this, you need some structural scaffolding, workflow handling and data management techniques to ensure the AI pipelines and experiences function reliably at scale. One of the things that makes using models in production difficult is their inherent probabilistic nature. APIs in previous paradigms were deterministic and programmed to do things in very specific conditions and formats. The crux of most product challenges involved comes down to this:
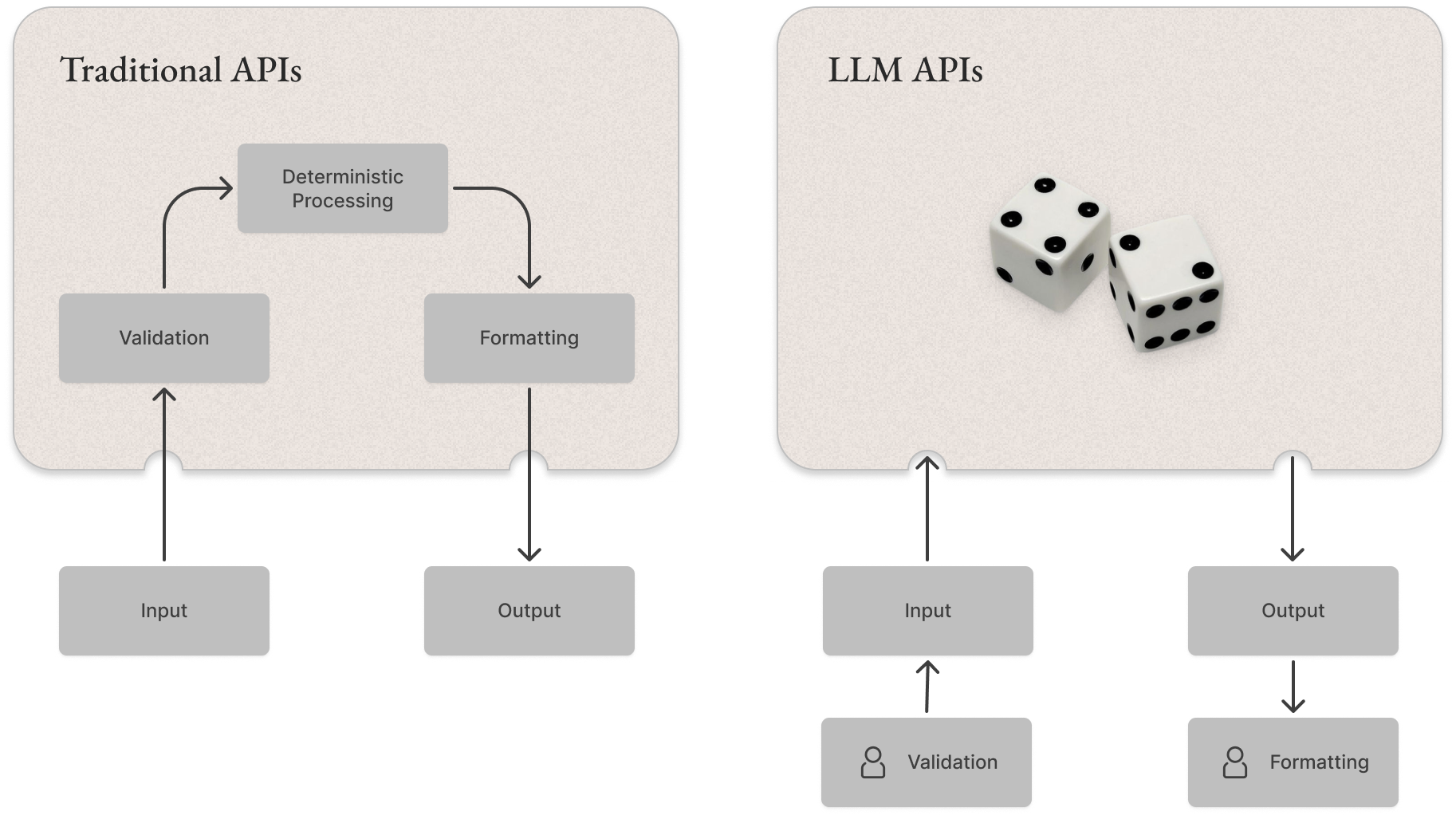
To solve for this, you essentially need to simulate proto-AGI for the use-case and domain you’re building in. It needs to be a subject matter expert and know how to deal with ambiguous edge cases without explicit definition and training. One approach to getting as close as possible is by scaffolding and engineering around this in the application realm.
Data structures: LLMs are basically completion machines that figure out what token to output next. It only works on the next token at a time and the next token is determined, at the root of it, by a differentiable function invoked at scale. A coherent set of tokens make up words and, eventually, a sentence. This is just one shape of the output it is capable of creating, along the way it has also learned (or can be taught) how to mimic machine-readable language too. An interesting and amusing outcome is that the shape and ergonomics of the output from an LLM does not have to resemble human-readable text.
This means we can now output any data structure that follows a discernible ruleset. This could be machine code, JSON, YAML, LaTeX, markdown and even biomimetic data structures like protein sequences. This turns language model APIs into essentially a synthesis adapter for a vast majority of use cases. Everything from translation, business logic, transformation, schema formatting, extrapolation, validation, experimentation, aggregation etc can be partially or completely done in the inference realm instead of the application layer. Offloading complex systems and engineering workflows to the model layers. This abstraction is fundamental to AI being used to power more than chat and language interfaces, and is at the root of its accelerant trait.

Decomposition & Chaining: Getting the desired result in a single prompt/response is a great way to proof-of-concept. However, as the problem complexity inevitably increases while solving real world problems, this quickly becomes a limiting factor along with context-size limitations for prompting. If you decompose the problem into several stages and build a pipeline/chain that is step-optimised to produce the output you need - you build a much more resilient and scalable system.
Machine-interface Models: this an another fun one we use across the board at Qatalog. MiMs are designed to be interfacing directly with machines, with no human in the loop. These “adaptors” are designed to produce one probabilistic output in a larger chain of outputs that are used to compose the end result.
Federation & Multiplexing: another approach we concocted at Qatalog is building a recursive multiplexer that knows which set of models, prompts, helper functions and marshallers to use depending on the problem. This is very powerful and I suspect will be established as the architecture of choice in the near term for building multi-faceted and full-stack AI products. I’m hoping to publish some of the seminal work we’ve done here shortly.

4. Correcting errors: guarding for technical limitations
LLMs do not conceptually understand its own outputs. In simple terms, it makes next word predictions that are closest to what it learned during training. In the absence of relevant training data, it outputs whatever else is closest probability - sometimes these are factually incorrect/incoherent, also called ‘hallucinations’.
LLMs are typically trained on content crowd-sourced through online platforms and/or have error-prone collection protocols. Popular language models are also designed to encourage informativeness over faithfulness. Use-cases like search, task assistants, healthcare and other critical services need significant safeguarding around collection protocols, faithfulness and accuracy before production use.
You need to test the data-collection protocol, the model, the inference outputs and the user experience - and do so programmatically, at scale. Models can be evaluated using a variety of metrics like Perplexity, but also using more niche metrics like BLEU, ROUGE etc that are relevant to the use-case. There is also new interesting research on how models can evaluate themselves. We need more structural tooling, methodologies and processes to ensure the models are functioning within expected parameters and are not introducing any risk, factual errors or bias in the output. Additionally, incorporating programmatic reinforcement features at the application layer to report, identify and guard against negative outputs in the future.
5. Capture value: building AI businesses
This is a defining moment in the history and trajectory of businesses as companies now have the ability to leverage AI to gain a competitive edge and scale in ways previously impossible. For many companies, AI is a tool to improve existing products while for others, it is the foundation of their entire business. Fullstack AI companies, such as Qatalog and inevitably others, are being built from the ground up with a focus on AI-native products as well as AI-powered operations. Everything from product, sales, marketing, onboarding, support, success and customer interactions are being re-imagined with AI. All previous references and benchmarks for costs of running, operating and scaling a business are about to be restructured and reset.
Attempts at driving value with AI seem to mostly create new use-cases and behaviours, while most of the immediate value is in retrospectively applying the technology to existing problems. Capturing value in AI today involves leveraging the technology to achieve one of the following: faster time to value in existing products, lowering costs of production, increasing scalability of business functions, increasing market reach by customisation, increasing productivity of individuals, automated personalisation or reducing the bottlenecks in coordination. Applying this requires careful evaluation of the existing processes and identifying insertion points for the technology and restructuring the process for the desired outcome.
To build a sustainable business with AI, there are three possible moats to optimize for: first, unique product infrastructure built with domain insights that enable a better service; structured in a way that can be leveraged by AI. Second, access to proprietary data that can be used to train and fine-tune models to an efficacy level that is impossible otherwise. Third, access to compute/talent that it can use to build and scale faster than competition. Of course, moats don’t last forever - if it did, England would still be ruled by the Romans.
Conclusion
On a practical level, we can ensure that this technology is used responsibly and effectively in a few different ways: by thinking in domains, breaking the skeuomorphic barrier, redefining with AI-native solutions, guarding against technical limitations, and leveraging the technology where it creates most value.
But on a more human level, we are well on our way to acquiring an intelligent exoskeleton for our brains. We can achieve much more - so much more - with so much less. We’re about to witness the restructuring of experiences, businesses, computing and other familiar paradigms unfold right in front of us. Like most new technologies, the initial demos and possibilities are fascinating, but the real tangible feedback is in the things we will never have to do again. In the coming years, we will see these new paradigms used in ways we would never expect, and helping us to create products and services we never thought possible.
What a time to live.
If you have thoughts on the post (or looking for an AI product/eng role), reach me on Twitter.